4 gif-IDA exchange format
4.1 General
The quality of the data to be exchanged primarily depends on the defined rules being unique and verifiable. The sender should already be able to check the quality of the data provided or validate it against agreed rules. Underlying rules must be automated on this basis and verifiable. In recurring exchange processes in particular (e.g., monthly reporting), this sign of quality is extremely important. The sender and recipient should be able to focus on their key tasks, instead of having to involve extensive resources in carrying out data quality checks. For this reason, gif has decided to recommend XML formats (Extensible Markup Language) for exchanging data. Furthermore, XML files provide the option of exchanging sizeable file structures in one file container irrespective of the platform and implementation.
XML schemas (or XSD for XML Schema Definition) form part of this guideline per subset, describing the structure of the XML documents. All content, structure and format specifications, and reliable attributes are described via an XML schema per subset. The XML schemas will in future be updated with each new version of the complete data field catalog. All versions of the complete data field catalog are permanently available with their respective XML schema per subset.
XML formats can only be automatically interpreted and validated with specialist tools and the corresponding expertise. So they are suitable for use as a source by software vendors and experienced IT departments. If it is necessary to exchange data between non-certified systems, the ICRED can convert the respective data to tabular CSV format (comma-separated values), see also section 4.4.
4.2 Formatting guidelines
4.2.1 Data object and identification number
Each entity to be taken into consideration in the data exchange requires a unique identification number. The identification number is a fixed component of each subset in each case. As part of the data exchange according to gif-IDA, the sender and recipient agree on a one-time basis which system will be the lead system for allocating the identification number. Some subsets also allow the sender and recipient ID to be transmitted redundantly. If there is repeated (e.g., monthly) data exchange, the allocation of the identification number (or the combination of identification numbers of higher-level hierarchies) is to allow the position of the entity in the data model to be derived.
Normally, the recipient transfers the appropriate identification number for identifying the asset (e.g., client) as well as the identification numbers of the properties. All deeper entity hierarchies (e.g., lease contract numbers) are specified by the sender. Exceptions may occur when data sets are initially transferred, e.g., following a management transfer. If the property was already owned by the recipient, before the sender was assigned responsibility for administration/ management, the sender initially accepts all the recipients identification numbers. New identification numbers for new entities (e.g., for new lease contracts, leasable space) are assigned by the sender and accepted by the recipient.
Any different arrangements must be explicitly agreed between the sender and recipient.
4.2.2 Validities
The following information must be present with all data objects:
- Start of validity: The start of validity at least must be specified for all entities (data objects) to be imported.
- End of validity: The end of validity is a field delivered with all entities (data objects): asset, building, land, and rental units. If information on the end of validity is missing, it is assumed that validity is unlimited. If the validity of the entities (data objects) is unlimited (e.g., unlimited lease contract), this data field is transferred empty.
- Data area: The data area specifies the aim or purpose of the data to be imported for example, budget data, forecast data, actual data. As an option, a description can also be provided as free text.
- Combination of assets, buildings, rental units: If existing entities (data objects), such as two rental units, are combined, the end of validity for one or both of the entities (data objects) is set in the delivery system. No entities (data objects) may be deleted in the delivery system, as the data fields in the target system are not updated accordingly as part of the data exchange.
4.2.3 Formats
The following formatting rules are applicable for the various types of data field:
- Decimal display: In accordance with DIN EN ISO 80000: The period is the separating character; there is no digit grouping, and numbers less than 1 have a leading zero.
Examples: 0.55, 16332.63456, -44.673 - Negative values: Minus sign to the left of the numerical amount
Example: -200.00 - Entity/ data object identifiers: It is necessary to indicate all higher-level data objects of relevance for the data object (e.g., company). If required, these are indicated by the recipient.
If certain higher-level structures are not relevant for the data object (e.g., property company/ SPV), the identifier component remains empty.
Unavailable identifier components are supplemented with "filler zeros".
Data object identifiers should only comprise capital letters A to Z, digits, and the characters '_' or '-', e.g.: MA0001, MA0001_DE. In particular, special characters are not allowed in the entity (data object) identifiers.
The NAME field must always be completed for new entities (data objects).
The various amounts in data fields are formatted in accordance with the following rules: - Percentage values: Without percentage sign as absolute value
Examples:
5% becomes 0.05
62.75% becomes 0.6275
110% becomes 1.10 - Amount of money: Indicated as a decimal number plus currency in accordance with ISO 4217 (currency indicator is optional, provided it has already been specified for the entity or higher-level entity)
- Length/ space: Indicated as a decimal number. Measuring unit based on SI system in meters, alternative measuring units can optionally be indicated based on list of attributes.
- Date values: In accordance with ISO 8601: YYYY (year only), YYYY-MM (year and month), YYYY-MM-DD (for exact day)
Example: December 6, 2013 becomes 2013-12-06 - Duration (of time): In accordance with ISO 8601
Example: 1 year and 3 months becomes P1Y3M - Logical value: According to https://www.w3.org/TR/xmlschema2/#boolean True = 1, false = 0 Statement is true or false Example: 1
- Country: In accordance with ISO 3166-1 ALPHA-3
Examples:
Germany becomes DEU
The United States becomes USA - Language: In accordance with RFC 1766
Examples: de-DE, de-AT, en-US, en-GB, etc.
4.3 Data exchange via XML files
With each version of the complete data field catalogue, XSD files will be published containing the XML schema per subset. The XML schema describes data types in a complex schema language individual XML schema instances (documents). In future, XSD requirements for rule sets will also be published; they will serve as filters on the XSDs of a subset. A detailed technical description, which forms part of this guideline, can be found in Annex “H.3.”
Technical description of zgif format in version “.0.”
4.3.1 Elements of XML data exchange format
The gif exchange format comprises the following elements:
- Content and structural data Information on all files transferred within the data exchange process, as well as the master/ meta data on the actual data exchange, such as date created, validation date, version, created by, language, etc. (see file description of maniftest.xml, mimetype, type, meta.xml)
- Data files: These elements contain the actual data on the exchange in accordance with the specified format structure. If more than one period is exchanged, these files are available per period (see file description of maindata.xml, periods.xml).
- Documents: As an option, accompanying documents (e.g., lease contracts, invoices, etc.) can be transferred on any date (see description of objects directory).
- Schemas: As an option, the schema applicable for each XML file can also be transferred.
- Rule sets: Any rule sets agreed are an integral element of the data exchange format.
The data exchange process for all elements is carried out via a zipped data container (zgif). The zipped gif data exchange format (zgif for short) is the central format for transmitting process-related data, as defined by gif. The "zgif" file suffix was chosen primarily because it does not yet have any other significance as a file suffix in IT terms. This prevents any risk of confusion. The "z" stands for "zip" - so it is immediately clear that it is a ZIP container, which can be decompressed using a standard ZIP decoder. The second part of the suffix "gif" corresponds to the abbreviation of the format publisher, i.e., gif.
4.3.2 Knowledge base
- dropped -
4.4 Tabular exchange via CSV files
If it is necessary to exchange data between non-certified systems, please refer to the following specifications for the tabulated exchange of data via CSV (comma-separated Values). gif provides a separate converter for this purpose (ICRED). A detailed technical description, which forms part of this guideline, can be found in Annex H.4.
4.4.1 Transfer tables
To exchange data in CSV format, the Excel tables transferred with each subset can be used for the technical definition. The lead for the technical data field names is provided by the respective XSD definition.
The following tables form part of the CSV-based data exchange process:
- Metadata – META.csv
- Period – PERIOD.csv
- Connection – CONNECTION.csv
- Client - COM.csv
- Property/ assets – PROP.csv
- Land – LAND.csv
- Building – BUILD.csv
- Rental unit/ space – UNIT.csv
- Lease – LEASE.csv
- Contract object/ term – TERM.csv
- Contracting party – PARTNER.csv
- Service contract – CON.csv
- Project – PROJ.csv
- Loan – LOANS.csv
- Book entries – BOOK.csv
- Records – VOU.csv
- Valuations – VALUATION.csv
- Securities – SHARES.csv
4.5 Data exchange via JSON file
In addition to XML format, the JSON format has also become established over the last few years as a file format for the structured exchange of data. gif recommends using this format in addition to XML format as the preferred exchange format between sender and recipient, provided that the exporting and importing interfaces can process the file format. The structure corresponds almost exactly to the XML format in section 4.3.
4.6 Commercial digital twin
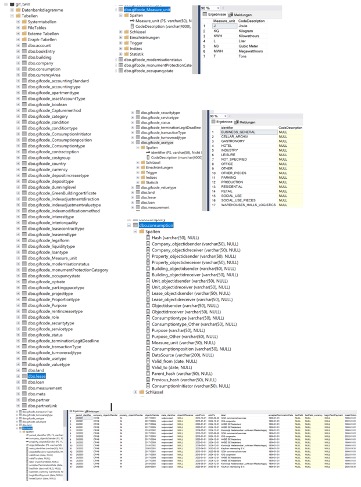
In version 3.0 of this guideline, the following scripts are provided to create a database in accordance with the gif data model:
- Script “010 crt gif_twin tables”: Executing this script creates the key entities (“Tabellen/ Tables”), their relationship with each other (“primary key” and “foreign key”) and their corresponding fields. The lists of attributes are created as separate tables with the prefix “gifcode”.
- Script “020 insert gifcode values”: Executing this script inserts the applicable attributes in the attribute list tables.
- Script “040 crt example data”: Executing this script creates example data in the generated table.
This forms the basis required for a commercial digital twin. Using the data model, it is possible in particular to show the most commercially important ESG data fields of asset management, owner structures and companies, including their accounting. The scripts are based on the structures of the Microsoft® SQL Server. The following Fig. 7 shows a number of screenshots from the resulting database.
Inserting the real data from the upstream systems into these structures is a specific task to be assigned. However, the digital twin provides a basic harmonized structure to which further third-party systems can easily connect.